1. 项目背景与目标 1.1 为什么选择 A3C 来玩超级马里奥? 超级马里奥是一个经典的横版过关游戏,玩法是简单,但是环境比较复杂:玩家要面对敌人、陷阱、跳跃平台,还要在有限时间内快速决策。实验case :
状态空间是高维的(游戏画面本身就是像素矩阵)
行动结果对未来奖励有长远影响(跳跃错过管道可能直接失败)
游戏场景变化多端,能充分考察智能体的泛化能力
因此,我们打算用 A3C(Asynchronous Advantage Actor-Critic) 来实现,A3C 是一种经典的深度强化学习算法,能够通过 多线程并行采样 加速训练,并且结合 Actor-Critic 框架 来提升策略收敛的稳定性,具体可参考上篇 。用它来解决马里奥问题,顺便还可以实践强化学习的 理论价值 和 工程落地能力 。
1.2 马里奥环境中的难点 在实现过程中,我们需要解决几个关键问题:
高维状态空间 :输入是 240×256 的彩色像素画面,直接学习难度极高,必须通过卷积网络提取特征,并通过灰度化、缩放、帧堆叠等方式进行状态压缩稀疏奖励问题 :游戏的“通关奖励”非常稀疏,大部分时间智能体得不到正向反馈。如果不加引导,智能体可能只会停留在原地或做无意义动作,这时就很需要 奖励塑形 ,例如根据分数、前进距离给予额外奖励实时决策与时序依赖 :马里奥游戏是一个典型的 部分可观测环境 :单帧图像不足以判断状态(如是否在跳跃过程中)。必须引入 LSTM 这样的时序模型,来帮助智能体记忆历史信息,做出更合理的决策
1.3 最终目标 在这样的背景下,我们的目标还可以更高一些,不仅仅是“让 AI 过关”,而是可以构建一个 完整的强化学习训练-测试-评估系统 。它应该具备以下特性:
能学会基本玩法 :通过奖励塑形和多进程训练,让智能体逐渐掌握跳跃、移动、攻击等操作能被系统评估 :不仅能通关,还能通过奖励曲线、通关率、视频回放等方式量化表现能支持扩展 :模块化设计,便于切换算法、替换模型,甚至迁移到其他游戏环境中
2. 游戏环境封装 2.1 环境介绍 马里奥环境来自 gym_super_mario_bros ,它是基于 OpenAI Gym 封装的 强化学习环境 ,在强化学习 (RL) 框架里,环境和智能体的交互遵循一个固定的规则:智能体选择一个动作 (action) → 环境返回下一状态 (state)、奖励 (reward)、是否结束 (done)、额外信息 (info) 。
基于此我们可以尝试用键盘玩马里奥,顺便熟悉一下环境。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 def play (): world, stage = 1 , 1 env = gym_super_mario_bros.make(f"SuperMarioBros-{world} -{stage} -v0" ) """ COMPLEX_MOVEMENT = [ ['NOOP'], # 0: 什么也不做 (No Operation) ['right'], # 1: 向右走 ['right', 'A'], # 2: 向右 + 跳 ['right', 'B'], # 3: 向右 + 加速跑 ['right', 'A', 'B'], # 4: 向右 + 跳 + 跑 (助跑跳) ['A'], # 5: 原地跳 ['left'], # 6: 向左走 ['left', 'A'], # 7: 向左 + 跳 ['left', 'B'], # 8: 向左 + 跑 ['left', 'A', 'B'], # 9: 向左 + 跳 + 跑 ['down'], # 10: 下 (蹲下,进水管/趴下) ['up'], # 11: 上 (例如爬藤蔓) ] """ env = JoypadSpace(env, COMPLEX_MOVEMENT) pygame.init() screen = pygame.display.set_mode((256 , 240 )) pygame.display.set_caption("Keyboard Play Super Mario Bros (Complex)" ) clock = pygame.time.Clock() action = 0 done = True state = env.reset() running = True while running: for event in pygame.event.get(): if event.type == pygame.QUIT: running = False keys = pygame.key.get_pressed() if keys[pygame.K_LEFT] and keys[pygame.K_SPACE]: action = 7 elif keys[pygame.K_LEFT]: action = 6 elif keys[pygame.K_RIGHT] and keys[pygame.K_SPACE] and keys[pygame.K_LSHIFT]: action = 4 elif keys[pygame.K_RIGHT] and keys[pygame.K_LSHIFT]: action = 3 elif keys[pygame.K_RIGHT] and keys[pygame.K_SPACE]: action = 2 elif keys[pygame.K_RIGHT]: action = 1 elif keys[pygame.K_SPACE]: action = 5 elif keys[pygame.K_DOWN]: action = 10 else : action = 0 state, reward, done, info = env.step(action) print (f"action: {action} , reward: {reward} , done: {done} , info: {info} " ) """ done: False, # 回合还没有结束 reward: 0.0, # 本次动作得到的即时奖励 action: 0, # 选择的动作编号 info: {'coins': 0, # 目前收集的金币数量 'flag_get': False, # 是否成功到达旗子,过关标志 'life': 2, # 当前剩余生命数 'score': 0, # 当前分数(环境内部累计的) 'stage': 1, # 当前关卡序号 'status': # 马里奥的状态,例如 'small'、'big'、'fire' 'time': 398, # 关卡剩余时间 'world': 1, # 当前世界序号 'x_pos': 40, # 横向位置(像素或格子) 'y_pos': 79} # 纵向位置 """ env.render() if done: if info.get('flag_get' , False ): world, stage = info['world' ], info['stage' ] + 1 try : env.close() env = gym_super_mario_bros.make(f"SuperMarioBros-{world} -{stage} -v0" ) env = JoypadSpace(env, COMPLEX_MOVEMENT) state = env.reset() print (f"切换到下一关: World {world} -{stage} " ) except : print ("已通关全部关卡!" ) running = False else : state = env.reset() clock.tick(60 ) env.close() pygame.quit() if __name__ == '__main__' : play()
原始的马里奥游戏提供了几十种按键组合(向左、向右、跳跃、加速、攻击等),这对智能体来说就像让初学者一次学完所有武术招式,难度太大。为了降低学习难度,我们使用 JoypadSpace 对动作空间进行简化,只保留最核心的动作,例如:
[向右走] → action = 1
[向右 + 跳跃] → action = 2
[向右 + 跑] → action = 3
[原地跳] → action = 5
[下蹲] → action = 10
这样,智能体可以专注于 前进、跳跃和避障 ,而不必分心去探索大量无关组合动作。简化后的动作空间不仅降低了探索难度,还显著加快了训练收敛速度。
2.2 奖励塑形 在强化学习中,奖励函数决定智能体学习方向。原始马里奥环境的奖励非常稀疏:智能体大部分时间得不到正向反馈(reward更新不及时),可能只会原地乱跳。奖励塑形策略 (自定义reward更新机制):
分数奖励 :根据吃金币、击败敌人等行为增加即时奖励通关奖励 :成功通关时给大额正奖励,失败(掉坑、超时)则给负奖励奖励归一化 :将奖励数值缩放,避免梯度过大导致训练不稳定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 def process_frame (frame ): """ 把原始游戏画面做预处理,变成适合神经网络输入的数据 """ if frame is not None : frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY) frame = cv2.resize(frame, (84 , 84 ))[None , :, :] / 255. return frame else : return np.zeros((1 , 84 , 84 )) class CustomReward (Wrapper ): """ 把环境原始观测处理成灰度 84×84 的输入,同时修改奖励信号,让训练更稳定 """ def __init__ (self, env=None , monitor=None ): super (CustomReward, self ).__init__(env) self .observation_space = Box(low=0 , high=255 , shape=(1 , 84 , 84 )) self .curr_score = 0 if monitor: self .monitor = monitor else : self .monitor = None def step (self, action ): state, reward, done, info = self .env.step(action) if self .monitor: self .monitor.record(state) state = process_frame(state) reward += (info["score" ] - self .curr_score) / 40. self .curr_score = info["score" ] if done: if info["flag_get" ]: reward += 50 else : reward -= 50 return state, reward / 10. , done, info def reset (self ): self .curr_score = 0 return process_frame(self .env.reset())
通过奖励塑形,智能体不仅能学到即时可见的动作好坏,还能朝着最终通关的长期目标努力。
2.3 状态预处理 游戏原始画面是 240×256 的 RGB 图像,直接作为网络输入计算量大、信息冗余多。我们通过以下方法进行预处理:
帧跳跃(Frame Skip) :每执行一次动作,跳过若干帧(例如 4 帧),减少交互次数,提高训练效率,并避免智能体关注不必要的“微小抖动”。 帧堆叠(Frame Stack) :将连续 4 帧画面堆叠作为状态输入,让智能体能感知运动趋势(例如判断马里奥是上升还是下落)。灰度化 + 缩放 : 将彩色图像转为灰度,保留核心信息,减少输入维度,缩放到 84×84 的固定分辨率,更适合卷积网络处理,同时降低计算量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class CustomSkipFrame (Wrapper ): """ 跳帧 + 状态堆叠,让智能体不用每一帧都观察和决策 1. 跳帧:一个动作连续执行多帧(skip 帧),减少环境计算量,提高训练效率。 2. 堆叠帧:将多帧图像堆叠起来作为状态输入,使智能体能感知运动方向和速度。 """ def __init__ (self, env, skip=4 ): super (CustomSkipFrame, self ).__init__(env) self .observation_space = Box(low=0 , high=255 , shape=(4 , 84 , 84 )) self .skip = skip def step (self, action ): total_reward = 0 states = [] state, reward, done, info = self .env.step(action) for i in range (self .skip): if not done: state, reward, done, info = self .env.step(action) total_reward += reward states.append(state) else : states.append(state) states = np.concatenate(states, 0 )[None , :, :, :] return states.astype(np.float32), reward, done, info def reset (self ): state = self .env.reset() states = np.concatenate([state for _ in range (self .skip)], 0 )[None , :, :, :] return states.astype(np.float32)
经过这些处理,原始画面被转化为一个 4×84×84 的张量 ,既保留了时序和关键信息,又方便神经网络高效学习。
3. 模型架构设计 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class ActorCritic (nn.Module): def __init__ (self, num_inputs, num_actions ): super (ActorCritic, self ).__init__() self .conv1 = nn.Conv2d(num_inputs, 32 , 3 , stride=2 , padding=1 ) self .conv2 = nn.Conv2d(32 , 32 , 3 , stride=2 , padding=1 ) self .conv3 = nn.Conv2d(32 , 32 , 3 , stride=2 , padding=1 ) self .conv4 = nn.Conv2d(32 , 32 , 3 , stride=2 , padding=1 ) self .lstm = nn.LSTMCell(32 * 6 * 6 , 512 ) self .critic_linear = nn.Linear(512 , 1 ) self .actor_linear = nn.Linear(512 , num_actions) self ._initialize_weights() def _initialize_weights (self ): for module in self .modules(): if isinstance (module, nn.Conv2d) or isinstance (module, nn.Linear): nn.init.xavier_uniform_(module.weight) nn.init.constant_(module.bias, 0 ) elif isinstance (module, nn.LSTMCell): nn.init.constant_(module.bias_ih, 0 ) nn.init.constant_(module.bias_hh, 0 ) def forward (self, x, hx, cx ): x = F.relu(self .conv1(x)) x = F.relu(self .conv2(x)) x = F.relu(self .conv3(x)) x = F.relu(self .conv4(x)) hx, cx = self .lstm(x.view(x.size(0 ), -1 ), (hx, cx)) return self .actor_linear(hx), self .critic_linear(hx), hx, cx
3.1 CNN 提取特征 输入(num_inputs, 84, 84),这里 num_inputs=4,因为我们前面做了 4 帧堆叠 ,每层卷积核大小 3×3,步长 stride=2 → 每过一层,特征图尺寸减半,经过 4 层卷积后,输出 32 × 6 × 6 的特征图。
这部分的作用是把原始像素图压缩成一个抽象的空间表示(比如马里奥在哪、敌人在哪、速度方向),方便后面 LSTM 使用。
3.2 LSTM 时序建模 1 self .lstm = nn.LSTMCell(32 * 6 * 6 , 512 )
输入维度:32 x 6 x 6 = 1152,也就是 CNN 压缩出来的特征向量,输出维度:512,表示 LSTM 的隐藏状态大小。
LSTM 的作用:
3.3 输出头Actor + Critic Critic 头 :输出一个标量,估计当前状态的价值 $V(s)$,用来评估 Actor 选择的动作好不好,减少训练的方差。Actor 头 :输出一个 num_actions 维的向量 → softmax 后就是动作概率分布,表示智能体的“策略”。
3.4 权重初始化 1 2 3 4 5 6 7 8 def _initialize_weights (self ): for module in self .modules(): if isinstance (module, nn.Conv2d) or isinstance (module, nn.Linear): nn.init.xavier_uniform_(module.weight) nn.init.constant_(module.bias, 0 ) elif isinstance (module, nn.LSTMCell): nn.init.constant_(module.bias_ih, 0 ) nn.init.constant_(module.bias_hh, 0 )
Xavier 初始化 :保证权重方差在前后层之间保持一致,避免梯度消失/爆炸偏置置零 :保证初始时 LSTM 不带偏向,学习过程更稳定
初始化的好坏,直接决定训练能不能顺利收敛。
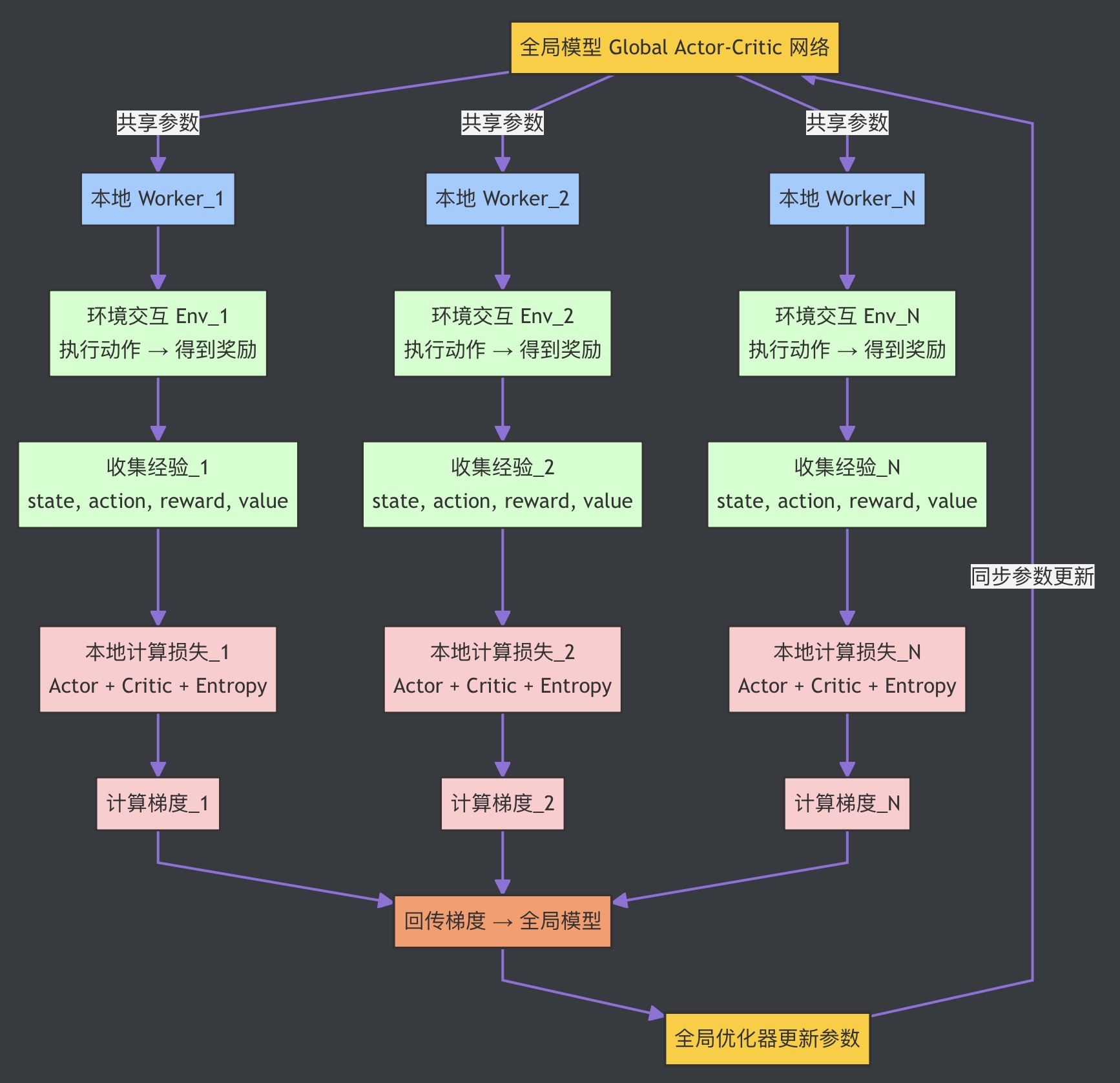
4. 多进程训练 4.1 train()函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 def train (opt ): torch.manual_seed(123 ) if os.path.isdir(opt.log_path): shutil.rmtree(opt.log_path) os.makedirs(opt.log_path) if not os.path.isdir(opt.saved_path): os.makedirs(opt.saved_path) mp = _mp.get_context("spawn" ) env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type) global_model = ActorCritic(num_states, num_actions) if opt.use_gpu: global_model.cuda() global_model.share_memory() if opt.load_from_previous_stage: if opt.stage == 1 : previous_world = opt.world - 1 previous_stage = 4 else : previous_world = opt.world previous_stage = opt.stage - 1 file_ = "{}/a3c_super_mario_bros_{}_{}" .format (opt.saved_path, previous_world, previous_stage) if os.path.isfile(file_): global_model.load_state_dict(torch.load(file_)) optimizer = GlobalAdam(global_model.parameters(), lr=opt.lr) local_train(0 , opt, global_model, optimizer, True ) local_test(opt.num_processes, opt, global_model) processes = [] for index in range (opt.num_processes): if index == 0 : process = mp.Process(target=local_train, args=(index, opt, global_model, optimizer, True )) else : process = mp.Process(target=local_train, args=(index, opt, global_model, optimizer)) process.start() processes.append(process) process = mp.Process(target=local_test, args=(opt.num_processes, opt, global_model)) process.start() processes.append(process) for process in processes: process.join() def create_train_env (world, stage, action_type, output_path=None ): env = gym_super_mario_bros.make("SuperMarioBros-{}-{}-v0" .format (world, stage)) if output_path: monitor = Monitor(256 , 240 , output_path) else : monitor = None if action_type == "right" : actions = RIGHT_ONLY elif action_type == "simple" : actions = SIMPLE_MOVEMENT else : actions = COMPLEX_MOVEMENT env = JoypadSpace(env, actions) env = CustomReward(env, monitor) env = CustomSkipFrame(env) return env, env.observation_space.shape[0 ], len (actions)
4.2 单个进程的训练 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 def local_train (index, opt, global_model, optimizer, save=False ): torch.manual_seed(123 + index) if save: start_time = timeit.default_timer() writer = SummaryWriter(opt.log_path) env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type) local_model = ActorCritic(num_states, num_actions) if opt.use_gpu: local_model.cuda() local_model.train() state = torch.from_numpy(env.reset()) if opt.use_gpu: state = state.cuda() done = True curr_step = 0 curr_episode = 0 while True : if done: h_0 = torch.zeros((1 , 512 ), dtype=torch.float ) c_0 = torch.zeros((1 , 512 ), dtype=torch.float ) else : h_0 = h_0.detach() c_0 = c_0.detach() if opt.use_gpu: h_0, c_0 = h_0.cuda(), c_0.cuda() local_model.load_state_dict(global_model.state_dict()) log_policies, values, rewards, entropies = [], [], [], [] episode_reward = 0 cleared = False for _ in range (opt.num_local_steps): curr_step += 1 logits, value, h_0, c_0 = local_model(state, h_0, c_0) policy = F.softmax(logits, dim=1 ) log_policy = F.log_softmax(logits, 1 ) entropy = -(policy * log_policy).sum (1 , keepdim=True ) m = Categorical(policy) action = m.sample().item() state, reward, done, info = env.step(action) state = torch.from_numpy(state) if opt.use_gpu: state = state.cuda() if info.get('flag_get' , False ): cleared = True done = True if curr_step > opt.num_global_steps: done = True if done: curr_step = 0 state = torch.from_numpy(env.reset()) if opt.use_gpu: state = state.cuda() episode_reward += reward values.append(value) log_policies.append(log_policy[0 , action]) rewards.append(reward) entropies.append(entropy) if done: break R = torch.zeros((1 , 1 ), dtype=torch.float ) if opt.use_gpu: R = R.cuda() if not done: _, R, _, _ = local_model(state, h_0, c_0) gae = torch.zeros((1 , 1 ), dtype=torch.float ) if opt.use_gpu: gae = gae.cuda() actor_loss, critic_loss, entropy_loss = 0 , 0 , 0 next_value = R for value, log_policy, reward, entropy in list (zip (values, log_policies, rewards, entropies))[::-1 ]: gae = gae * opt.gamma * opt.tau + reward + opt.gamma * next_value.detach() - value.detach() next_value = value actor_loss += log_policy * gae R = R * opt.gamma + reward critic_loss += (R - value) ** 2 / 2 entropy_loss += entropy total_loss = -actor_loss + critic_loss - opt.beta * entropy_loss writer.add_scalar(f"Train_{index} /TotalLoss" , total_loss.item(), curr_episode) writer.add_scalar(f"Train_{index} /ActorLoss" , actor_loss.item(), curr_episode) writer.add_scalar(f"Train_{index} /CriticLoss" , critic_loss.item(), curr_episode) writer.add_scalar(f"Train_{index} /Entropy" , entropy_loss.item(), curr_episode) writer.add_scalar(f"Train_{index} /EpisodeReward" , episode_reward, curr_episode) writer.add_scalar(f"Train_{index} /Cleared" , int (cleared), curr_episode) optimizer.zero_grad() total_loss.backward() for local_param, global_param in zip (local_model.parameters(), global_model.parameters()): if global_param.grad is None : global_param._grad = local_param.grad optimizer.step() curr_episode += 1 print ( f"[Process {index} ] Episode {curr_episode} | " f"Reward: {episode_reward:.2 f} | " f"Cleared: {'Yes' if cleared else 'No' } | " f"TotalLoss: {total_loss.item():.4 f} | " f"ActorLoss: {actor_loss.item():.4 f} | " f"CriticLoss: {critic_loss.item():.4 f} | " f"Entropy: {entropy_loss.item():.4 f} " ) if save and curr_episode % opt.save_interval == 0 : torch.save(global_model.state_dict(), f"{opt.saved_path} /a3c_super_mario_bros_{opt.world} _{opt.stage} " ) if curr_episode >= int (opt.num_global_steps / opt.num_local_steps): print (f"Training process {index} terminated" ) if save: end_time = timeit.default_timer() print (f'Total training time: {end_time - start_time:.2 f} s' ) return
训练日志:
1 2 3 4 5 6 7 8 [Process 0] Episode 1 | Reward: -0.20 | Cleared: No | TotalLoss: 4.4672 | ActorLoss: -5.1896 | CriticLoss: 0.5195 | Entropy: 124.1912 [Process 0] Episode 2 | Reward: 2.30 | Cleared: No | TotalLoss: 43.5234 | ActorLoss: -40.6037 | CriticLoss: 4.1615 | Entropy: 124.1819 [Process 0] Episode 3 | Reward: 2.50 | Cleared: No | TotalLoss: 55.0827 | ActorLoss: -45.4405 | CriticLoss: 10.8840 | Entropy: 124.1825 [Process 0] Episode 4 | Reward: -1.20 | Cleared: No | TotalLoss: -48.3509 | ActorLoss: 53.7558 | CriticLoss: 6.6465 | Entropy: 124.1659 ... ... ... ...
[Process 0] Episode 1 :来自 第 0 个 Worker 进程 ,这是它的 第 1 个 episode (从环境 reset 开始到终止)。Reward: -0.20 :本次 episode 的累计奖励是 -0.20 ,表明智能体在第一轮尝试中表现很差(可能掉坑、被怪物碰到,奖励为负),这是正常现象,初期策略接近随机,几乎没有生存能力。Cleared: No :没有通关 ,早期训练阶段几乎所有 episode 都是失败的。TotalLoss: 4.4672 :总的训练损失(Actor + Critic - β·Entropy),数值并不是越低越好,而是随着训练过程动态波动。ActorLoss: -5.1896 :策略梯度损失(带优势函数的 $log π(a|s)$)。这里是 负值 ,说明模型在尝试调整策略去增加某些动作的概率,在 early stage,负的 actor loss 很常见,因为 GAE 给出的优势值可能是负的。CriticLoss: 0.5195 : 价值函数($V(s)$)的均方误差损失,数值不大,说明 Critic 对部分状态的价值估计已经在收敛。Entropy: 124.1912 :策略分布的熵值(衡量探索程度),值很大,表示当前策略接近 均匀随机 ,几乎所有动作的概率差不多。这是好事,说明智能体在初期保持了充分探索,不会过早收敛到坏策略。
4.3 总结
train() :负责环境准备、加载模型、启动多个进程(并行训练 + 测试)local_train() :单个进程的训练逻辑 → 环境交互 → 收集轨迹 → 计算损失 → 梯度上传 → 全局更新全局同步 :本地模型参数从全局拉取,训练后梯度上传,保证所有进程共享一份最新策略测试流程 :单独起一个 local_test 进程,不采样动作,而是用贪婪策略评估当前表现
5. 优化器实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class GlobalAdam (torch.optim.Adam): def __init__ (self, params, lr ): super (GlobalAdam, self ).__init__(params, lr=lr, foreach=False ) for group in self .param_groups: for p in group['params' ]: state = self .state[p] state['step' ] = torch.tensor(0. ) state['exp_avg' ] = torch.zeros_like(p.data) state['exp_avg_sq' ] = torch.zeros_like(p.data) state['step' ].share_memory_() state['exp_avg' ].share_memory_() state['exp_avg_sq' ].share_memory_()
GlobalAdam 是为了 在多进程环境下安全地更新全局模型参数 。它保留了 Adam 的梯度自适应能力,同时保证 每个 Worker 看到的是同一套动量和步数 ,保证 A3C 的训练稳定性,如果没有 share_memory_(),各 Worker 的梯度就只能独立更新本地模型,全局模型不会正确同步 。
6. 测试与评估 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 def play (opt ): torch.manual_seed(123 ) model = ActorCritic(num_states, num_actions) if torch.cuda.is_available(): model.load_state_dict(torch.load("{}/a3c_super_mario_bros_{}_{}" .format (opt.saved_path, opt.world, opt.stage))) model.cuda() else : model.load_state_dict(torch.load("{}/a3c_super_mario_bros_{}_{}" .format (opt.saved_path, opt.world, opt.stage), map_location=lambda storage, loc: storage)) model.eval () env, num_states, num_actions = create_train_env(opt.world, opt.stage, opt.action_type, "{}/video_{}_{}.mp4" .format (opt.output_path, opt.world, opt.stage)) state = torch.from_numpy(env.reset()) done = True while True : if done: h_0 = torch.zeros((1 , 512 ), dtype=torch.float ) c_0 = torch.zeros((1 , 512 ), dtype=torch.float ) env.reset() else : h_0 = h_0.detach() c_0 = c_0.detach() if torch.cuda.is_available(): h_0 = h_0.cuda() c_0 = c_0.cuda() state = state.cuda() logits, value, h_0, c_0 = model(state, h_0, c_0) policy = F.softmax(logits, dim=1 ) action = torch.argmax(policy).item() action = int (action) state, reward, done, info = env.step(action) state = torch.from_numpy(state) env.render() time.sleep(1 / 30 ) if info["flag_get" ]: print ("World {} stage {} completed, reward:{}" .format (opt.world, opt.stage, reward)) break
模型效果:
world 1 stage 1
world 3 stage 1
world 7 stage 1
总结:
加载训练好的全局模型 → 保证策略质量初始化环境与状态 → 保持与训练一致初始化/更新 LSTM 隐状态 → 记忆连续动作信息选择动作 → 与环境交互 → 获取奖励 → 执行策略并收集指标通关/结束检测 → 判断策略效果可视化 + 视频录制 → 便于分析和展示
评估阶段就是让训练好的模型去玩游戏,记录每一步表现,同时生成视频来观察策略是否稳健。
7. 实际训练表现 7.1 训练关卡的选择 智能体的学习效果与环境复杂度密切相关。为了循序渐进地提升智能体的能力,我们通常会选择不同难度的关卡进行训练,比如:
世界 1-2 :包含管道与天花板,强调 跳跃精度 与 避障 策略世界 3-1 :出现飞行敌人和平台跳跃,考验智能体的 时机把握 与 动态环境适应能力 世界 7-1 :敌人密集、地形复杂,属于 高难度场景 ,用于检验智能体在复杂环境中的泛化能力
这种由浅入深的关卡设计,类似人类玩家的学习过程:先掌握基本操作,再逐步挑战更复杂的场景。
7.2 训练时间与资源开销 训练时间的长短取决于 硬件条件 与 并行度 :
数小时 :智能体可以学会基础操作,例如避免直接碰撞敌人、尝试跳跃数十小时 :策略逐渐成型,能够更合理地处理障碍,表现出较为稳定的存活能力几天 :在多核 CPU + GPU 的支持下,智能体能够学习到较复杂的动作组合,甚至可以通关
如果仅依靠单机 CPU,训练效率会显著下降,可能需要几天甚至更久的时间来完成同等水平的学习。
7.3 训练成果 经过充分训练后,智能体逐渐展现出与人类玩家类似的行为模式:
避障能力 :面对前方的敌人,智能体能够选择跳跃或绕开,而不是盲目前进。跳跃掌握 :能够在坑洞前做出恰当的起跳动作,并且学会通过踩击敌人获取奖励。通关能力 :在部分关卡中,智能体可以稳定地完成整局游戏,并触发 flag_get = True,即成功到达终点。
与训练初期的“乱跑乱跳”相比,成熟的智能体表现更接近一个“熟练但偶尔失误”的人类玩家。
8. 工程化实现要点 8.1 LSTM 状态管理:detach避免梯度爆炸 在 A3C 中,我们采用 LSTM 单元 来建模时间依赖性,让智能体能够记忆过去的状态和动作。梯度爆炸 或 显存泄漏 。
解决办法是在每一轮 episode 开始时,显式执行:
1 2 3 4 5 6 if done: h_0 = torch.zeros((1 , 512 )) c_0 = torch.zeros((1 , 512 )) else : h_0 = h_0.detach() c_0 = c_0.detach()
这样,新的 episode 使用 干净的初始状态 ;未结束的 episode 则通过 detach 切断梯度回溯,避免跨 episode 梯度累计。
8.2 容错机制:环境异常自动reset 游戏环境(特别是复古模拟器)可能会因为 非法动作 、内存错误 或 渲染问题 崩溃。如果训练过程缺乏容错机制,整个多进程系统就会挂掉。
因此,代码中设计了 自动 reset 机制:
1 2 if done: state = torch.from_numpy(env.reset())
一旦游戏失败或环境异常,智能体立即重置到初始状态,继续学习。这样保证了训练过程的 鲁棒性 ,不会因为单个环境问题影响全局训练。
8.3 模块化设计 为了便于维护与扩展,整个系统采用了 模块化设计 :
env :环境封装层,负责状态预处理(灰度化、帧堆叠、缩放)和动作空间简化model :Actor-Critic 网络定义,包含 CNN 特征提取、LSTM 时序建模、Actor & Critic 输出optimizer :自定义 GlobalAdam,支持多进程共享梯度更新process :多进程 Worker 管理,确保并行训练与测试正常运行train :训练逻辑,包括 rollout、GAE 优势估计、损失计算与梯度回传test :测试与评估,加载 checkpoint 并可视化智能体表现
这种分层结构使得工程更接近 生产级系统 ,方便在未来替换不同算法(如 PPO、IMPALA)、接入不同环境(如 Atari、Gym Retro)。
9. 性能优化技巧 9.1 帧跳跃 (Frame Skip) + 状态堆叠 (Frame Stack) 为什么需要帧跳跃? 60 FPS ,如果每一帧都作为一步训练,计算量巨大,而且很多相邻帧几乎没有差别。因此,我们让智能体 每隔几帧执行一次动作 ,比如 skip=4,这意味着智能体每 4 帧才更新一次决策。这样做有两个好处:
降低计算量 :训练步数减少到 1/4增强动作一致性 :连续几帧保持相同动作,更符合人类操作习惯
为什么需要状态堆叠? 短期局部时序 和长期全局时序 ,大大提升学习效率。
9.2 奖励塑形 (Reward Shaping) 原始奖励的问题 到达终点旗子 ,但如果智能体只有在通关时才获得奖励,它会面临 稀疏奖励问题 :前面几万步几乎得不到反馈,学习非常困难。
奖励塑形的做法
前进奖励 :向右走一步给一个小奖励,避免原地不动金币奖励 :吃到金币/道具给额外奖励,鼓励探索死亡惩罚 :掉坑、碰怪物扣分,避免鲁莽尝试
通过这种“奖励引导”,智能体会更快学会走、跳、避障,最终再通过通关奖励来强化全局目标。
9.3 多进程并行 (Asynchronous Workers) A3C 的核心思想就是 异步并行 :同时运行多个环境,每个环境独立采样轨迹并更新全局模型。
采样效率高 :相比单线程采样,多进程能更快收集经验,GPU 不会闲置探索更全面 :不同 Worker 的随机性让智能体走出不同路径,避免陷入局部最优训练更稳定 :异步更新相当于一种“噪声正则化”,让全局参数更新不会被单一轨迹支配
如果没有并行机制,智能体在复杂关卡(如 3-1、7-1)几乎不可能在合理时间内学会通关。
10. 扩展与改进方向 在前面的实现中,我们已经基于 A3C + LSTM 搭建了一个能通关马里奥的智能体。但这并不是终点,强化学习在复杂环境中的探索还有很大空间。以下几个方向,可以作为改进或扩展的思路:
10.1 算法替换:更强大的策略优化方法 A3C 是早期的经典算法,但随着研究进展,出现了许多更稳定、更高效的替代方案:
PPO(Proximal Policy Optimization) :在更新策略时加入「约束」,避免一次更新过大导致策略崩溃。相比 A3C,PPO 在样本效率和收敛速度上表现更好,是目前游戏和机器人领域的主流选择SAC(Soft Actor-Critic) :通过 最大化熵 来鼓励探索,让智能体更具鲁棒性。在连续动作空间任务(如机器人操作)中尤其有效IMPALA、APPO 等分布式方法 :进一步放大并行规模,适合在大集群上运行,显著加快训练速度。
换句话说,A3C 是“起点”,但在更高要求的场景中,可以逐步迁移到这些更先进的算法。
10.2 结构优化:让模型更聪明 当前的 Actor-Critic 模型通常由 CNN + LSTM 构成,但我们可以借鉴深度学习中的最新进展:
注意力机制(Attention) :让模型“选择性关注”画面中的关键区域,比如马里奥和怪物,而不是盲目处理整张画面。这样不仅提高决策效率,还能减少无关干扰残差连接(ResNet-style) :在深层 CNN 中加入残差结构,缓解梯度消失问题,让模型可以更轻松地训练得更深,从而提取更复杂的特征
这类结构改进能让模型不仅“看得清”,还能“看得远”,在长时序任务中尤其有帮助。
10.3 训练策略:让智能体学得更快 强化学习的难点在于探索效率低,而合理的训练策略能显著改善:
课程学习(Curriculum Learning) :像人类学习一样,从简单任务逐步过渡到复杂任务。例如先在 1-1 学会走和跳,再放到 3-1 学习避难度更高的障碍,最后挑战 7-1跨关卡训练(Multi-Task Learning) :不局限于单一关卡,而是让智能体在多个关卡中同时训练。这样能提升泛化能力,避免过拟合到某一地图模仿学习 + 强化学习结合 :先通过模仿人类操作初始化策略,再用强化学习微调,能够大幅降低探索难度
这些方法能显著缩短收敛时间,让智能体更快达到可用水平。
10.4 应用拓展:从游戏到现实 虽然我们在马里奥上做实验,但本质上,这套框架可以推广到更广泛的领域:
通用游戏 AI :不仅限于马里奥,还可以用于 Atari、Minecraft、甚至 3D FPS 游戏,作为通用测试平台机器人控制 :现实中的机器人同样需要感知(相机、传感器)和决策(运动控制),和马里奥环境高度相似。经过适配后,可以让机器人学会走路、抓取物体、避障等技能自动驾驶与智能体仿真 :交通环境和复杂仿真同样依赖强化学习,算法优化和并行训练经验都可以迁移过去
11. 总结 本文尝试构建一个完整的深度强化学习系统,使用 A3C(Asynchronous Advantage Actor-Critic)算法 训练智能体玩超级马里奥游戏。该系统解决了高维状态空间、稀疏奖励和时序依赖等关键问题,实现了从环境封装、模型设计、多进程训练到性能评估的全流程。
核心要点
环境封装与预处理
通过 gym_super_mario_bros 和 JoypadSpace 简化复杂动作空间,降低智能体探索难度
奖励塑形 (Reward Shaping) :自定义奖励函数,结合即时分数奖励、通关大额奖励和失败惩罚,有效引导智能体学习
状态预处理 :采用帧跳跃 (Frame Skip)、帧堆叠 (Frame Stack)、灰度化和缩放,将原始像素输入压缩为 4×84×84 的张量,大幅提升训练效率
模型架构 (Actor-Critic with LSTM)
CNN 特征提取器 :处理视觉输入,提取空间特征
LSTM 时序建模 :记忆历史信息,解决部分可观测问题,使智能体能理解跳跃、移动等动作的连续性
双输出头 :Actor 输出动作概率分布,Critic 评估状态价值,共同优化策略
多进程并行训练 (Asynchronous Parallelism)
多个 Worker 进程并行与环境交互,收集经验,异步更新全局共享模型,极大加速样本收集和训练过程
自定义 GlobalAdam 优化器,通过 share_memory() 实现多进程间梯度同步和参数更新,确保训练稳定性
评估与可视化
独立的测试进程使用训练好的模型进行贪婪策略评估,生成通关视频和性能指标(如奖励曲线、通关率),直观展示智能体表现
工程化与性能优化
模块化设计 :环境、模型、训练、测试分离,便于维护和扩展
关键技巧 :LSTM 状态 detach() 防止梯度爆炸;帧跳跃与堆叠平衡效率与信息完整性;奖励塑形解决稀疏奖励问题
智能体最终能学会跳跃、避障、攻击等操作,在部分关卡达到稳定通关水平
12.备注 环境:
mac: 15.2
python: 3.12.4
pytorch: 2.5.1
numpy: 1.26.4
gym_super_mario_bros: 7.4.0
gym:0.25.1
tensorboardX:2.6.2.2
opencv-python:4.11.0.86
参考代码:https://github.com/vietnh1009/Super-mario-bros-A3C-pytorch
完整代码:https://github.com/keychankc/dl_code_for_blog/tree/main/029-a3c_super_mario_code
 基于此我们可以尝试用键盘玩马里奥,顺便熟悉一下环境。
基于此我们可以尝试用键盘玩马里奥,顺便熟悉一下环境。