[YOLO系列①] 物体检测评估指标和YOLO-v1实现思路
1.物体检测评估指标
1.TP / FP / FN / TN
这四个指标是分类任务的基础:
• TP(True Positive):预测为正,且是真正的正样本(比如检测到了一个人,且确实是人)
• FP(False Positive):预测为正,但实际上是负样本(检测到了人,但其实是背景或别的物体)
• FN(False Negative):实际是正样本,但没检测出来(图里有人,模型没发现)
• TN(True Negative):负样本预测为负(对物体检测来说,通常不关注 TN)
举个例子
| 名称 | 含义 | 举例(检测“猫”) |
|---|---|---|
| TP | 正确地检测出了一个猫 | 模型框住了图中的一只猫 |
| FP | 错误地检测出一个猫(其实没有猫) | 背景被误判为猫 |
| FN | 有猫但模型没检测出来 | 图里明明有猫,但模型漏掉了 |
| TN | 正确地没检测出负样本 | 背景没有猫,模型也没检测到 |
为何对物体检测来说,通常不关注 TN?
因为背景太多了,一张图中,除了少数目标区域,剩下都是背景(负样本)。比如整张图只有2只猫,剩下的几百万像素都是“不是猫”。所以 TN 的数量巨大无比,关注TN就没啥意义。
所以在物体检测中,正因为背景(负样本)太多且没明确边界,所以我们更关注的是检测出来的东西是否准确(TP / FP),和有没有漏检(FN)。
2.IoU(Intersection over Union)
预测框与真实框的重叠程度,IoU > 某个阈值(比如 0.5) 就认为检测成功(TP),否则认为是误报(FP)或漏检(FN)。
3.Confidence(置信度)
模型对这个框里确实有物体的信心程度,通常是一个介于 0 到 1 之间的小数,是模型对检测框中存在目标物体及其预测类别准确性的综合评判指标。
物体检测输出是:[类名, 置信度, 边界框坐标]。
作用:
1. 控制预测数量(过滤阈值),我们通常会设置一个阈值,比如 confidence > 0.5,只保留“自信”的预测。低于这个阈值的预测会被忽略,减少 FP(误报)
2. 用来画 PR 曲线、计算 AP,通过调整置信度阈值,我们会得到不同的:TP / FP / FN / Precision / Recall,画出 PR 曲线后还可以求AP(PR 曲线下的面积)
3. 排序时使用非极大值抑制,在非极大值抑制(NMS)中,为了去掉重复框,模型会:按置信度从高到低排序,保留最“自信”的框,去掉重叠度高的(IoU高)低置信度框
4.Precision(精度)
$$\text{Precision} = \frac{TP}{TP + FP}$$
预测为正的里面有多少是真的。
5. Recall(召回率)
$$\text{Recall} = \frac{TP}{TP + FN}$$
所有正样本中被预测出来了多少。
6.PR 曲线
通过调整置信度阈值,会得到一组 Precision 和 Recall 值,对这些点画图就得到了 PR 曲线。
高置信度:Precision 高,Recall 低,低置信度:Recall 高,Precision 低。
7.AP(Average Precision)
PR 曲线下的面积,也可以理解为对这条曲线的“积分”。不同的任务对 AP 的计算方法略有不同(见 VOC 和 COCO)。

8.mAP(mean Average Precision)
平均的AP,AP是对每一个类别算一个 AP,mAP 就是所有类别的 AP 的平均值
9.评估标准(VOC / COCO)
1. PASCAL VOC(早期标准)
来自 PASCAL VOC 挑战赛(2007 ~ 2012),经典但相对简单
2.COCO(更严格的现代标准)
来自 Microsoft 的 COCO 数据集。2015 后成为主流评估标准(比如 YOLOv5 默认用 COCO)
VOC vs COCO:
| 特性 | VOC | COCO |
|---|---|---|
| IoU 阈值 | 固定 0.5 | 0.5 ~ 0.95(步长 0.05) |
| AP 计算 | 简单插值 | 更精细插值 |
| 小物体评估 | 不考虑 | 特别考虑小/中/大物体性能 |
| 难度 | 相对简单 | 更严格全面 |
| 应用 | 早期模型测试 | 当前工业/学术主流(如 YOLO 系列) |
10.举个例子
1.示例场景
一张图中有 2 只猫(Ground Truth),使用VOC评估,模型预测了 3 个框,带有类别和置信度:
| 预测编号 | 预测框位置 | 类别 | 置信度 | IoU with GT |
|---|---|---|---|---|
| P1 | 猫1的位置 | 猫 | 0.9 | 0.75 |
| P2 | 猫2的位置 | 猫 | 0.7 | 0.55 |
| P3 | 没有猫的区域 | 猫 | 0.8 | 0.2(背景) |
2.先算 IoU,判断 TP / FP / FN
• P1:IoU 0.75 > 0.5 → TP
• P2:IoU 0.55 > 0.5 → TP
• P3:IoU 0.2 < 0.5 → FP
还有 Ground Truth 2 只猫都被命中,所以 FN = 0
| 指标 | 值 |
|---|---|
| TP | 2 |
| FP | 1 |
| FN | 0 |
3.计算 Precision 和 Recall
$$\text{Precision} = \frac{2}{2 + 1} = \frac{2}{3} \approx 0.67$$
$$\text{Recall} = \frac{2}{2 + 0} = 1.0$$
4.PR曲线
- 只保留置信度 > 0.85 → 只有 P1:TP=1, FP=0 → P=1.0, R=0.5
- 置信度 > 0.65 → P1+P2:TP=2, FP=0 → P=1.0, R=1.0
- 置信度 > 0.6 → P1+P2+P3:TP=2, FP=1 → P=2/3, R=1.0
将这些点连接起来形成 PR 曲线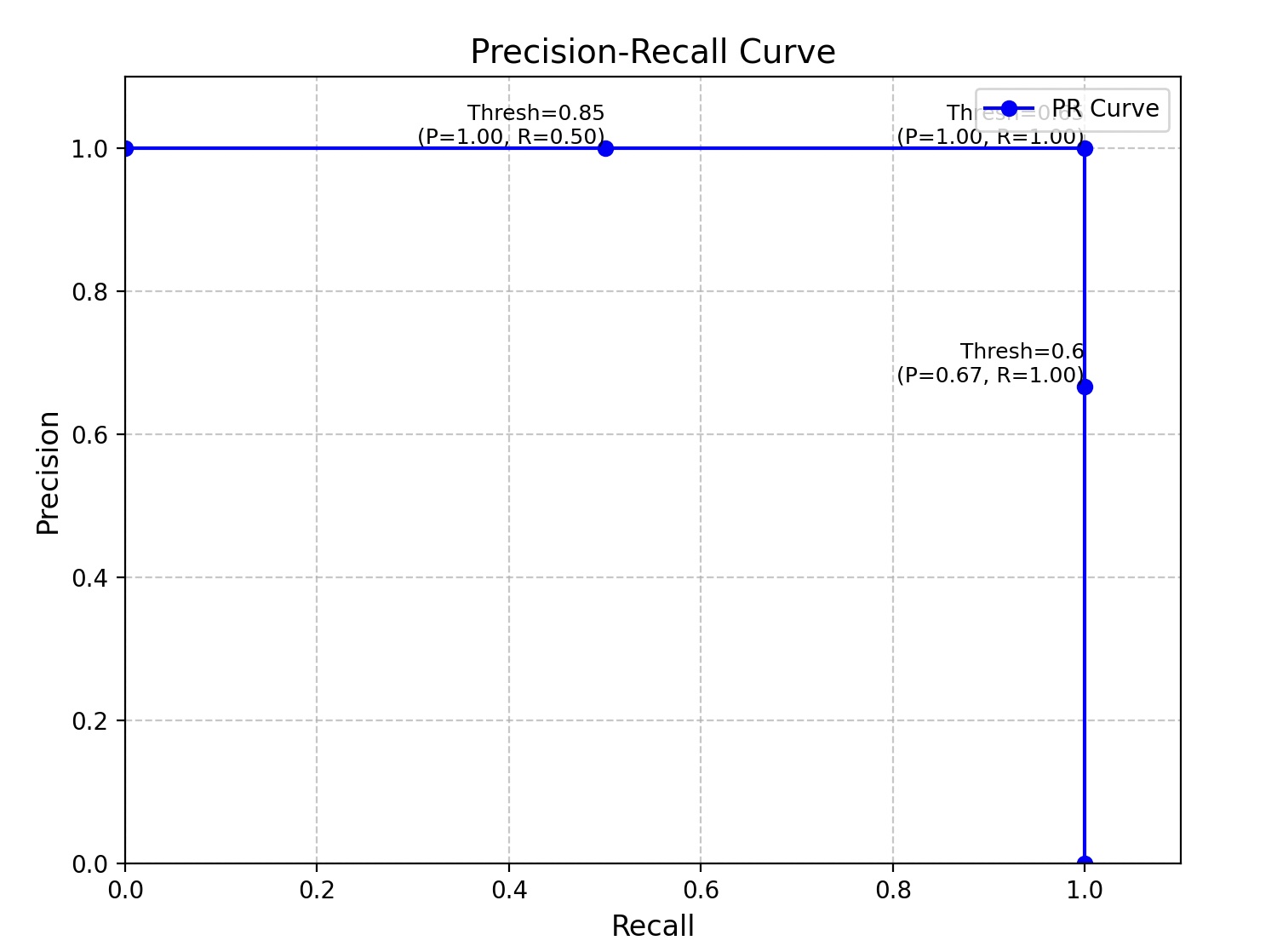
5.计算 AP 和 mAP
对这条 PR 曲线下的面积求和,就是这张图“猫”这一类的 AP,如果还有“狗”“人”等类别,每个类别都算一个 AP,再平均得到 mAP。
6.VOC vs COCO
在 VOC 中,IoU > 0.5 就算 TP,所以我们这里算的是 AP@0.5,在 COCO 中,还会算AP@0.5、AP@0.75、AP@0.95等,再平均得到更严格的 mAP。
2.YOLO-V1
1.目标检测方法
1.两阶段检测(Two-Stage)
代表模型:Faster R-CNN、Mask R-CNN
核心思想:“先粗选再精修”,就像选秀节目:
- 海选阶段(Region Proposal),用RPN(Region Proposal Network)快速生成约2k个候选框(可能含物体的区域)。特点是高召回率(宁可多选不错过),但框不准。
- 决赛阶段(RoI分类与回归),对每个候选框精细调整位置,并分类(如“猫”“狗”)。
优点是精度高(适合复杂场景,如小物体或密集目标),适合需要实例分割的任务(如Mask R-CNN),缺点是计算量大,速度慢(通常5~20 FPS),训练流程复杂(分阶段训练或端到端调参难)。典型应用有医学影像分析(肿瘤检测需高精度)、自动驾驶(高精度3D检测)、竞赛刷榜(COCO数据集冠军常客)等。
2. 单阶段检测(One-Stage)
代表模型:YOLO系列、SSD、RetinaNet
核心思想:“一步到位”,像快餐点单:
- 直接输出,对图像网格化,每个格子同时预测边界框和类别(无候选框步骤)。特点是速度快(YOLOv8可达100+ FPS)但易漏检小物体,部署简单(适合端侧设备如手机、无人机)。缺点是精度略低(尤其小物体检测),密集物体易重叠(如人群中的个体)。典型应用有实时视频分析(安防监控、直播质检)、移动端APP(手机AR贴纸、扫商品)、工业质检(快速检测缺陷)等。
3.技术演进趋势
- 两阶段的改进:
- 更高效的候选框生成(如Cascade R-CNN)
- 单阶段的突破:
- 提升小物体检测(YOLOv5的FPN+PAN结构)
- 动态标签分配(如OTA策略)
- 跨界融合:
- 单阶段模型通过蒸馏技术逼近两阶段精度(如YOLOv7)
2.YOLO产生背景

在 YOLO 出现之前,目标检测主流方法是两阶段的,例如
• R-CNN(2013):通过选择性搜索(Selective Search)生成候选框,然后再用 CNN 对每个框分类,mAP可达58.5,但速度慢
• Fast R-CNN(2015):引入 ROI Pooling 提高效率,但候选框还是靠外部生成(如选择性搜索),mAP 提升到 70,但 FPS 只有 0.5
• Faster R-CNN(2015):引入 Region Proposal Network(RPN),第一次实现了端到端训练,mAP 达到 73.2,速度提升到 7 FPS
这些方法虽然精度高,但速度较慢,难以应对实时场景。
YOLO(You Only Look Once)于 2015 年提出,核心思想是将目标检测转化为一个 回归问题,在一张图上直接预测边界框和类别:
特点:
- 单阶段、端到端架构:无需外部提议区域,整个检测过程一次完成
- 统一模型结构:整个网络是一个神经网络,直接从图像输入到边界框和类别输出
- 速度快:达到了 45 FPS,远高于前代方法,首次真正实现“实时目标检测”
- 简化流程:不依赖选择性搜索等复杂的预处理
虽然 YOLO-v1 的精度不如 Faster R-CNN,但胜在速度极快、部署简单,特别适合实时系统(如自动驾驶、监控等)
2.核心思想
YOLOv1的核心思想是将目标检测问题转化为一个单一的回归问题,一次性预测图像中所有目标的位置和类别,又叫一张图只看一次(You Only Look Once),也是YOLO名称的由来。
1.图像划分
如上左图将输入图像划分为 S × S 的网格(例如 S=7)。每个网格只负责预测其内部中心点落入该网格的物体。
2.预测多个边界框
每个网格单元预测 B 个边界框(通常 B=2),每个框包含:
• 坐标信息 (x, y, w, h)
• 置信度(confidence)= 物体存在概率 × IOU(预测框与真实框的重合程度)
上图中上部分显示了所有网格预测的大量框 + confidence。
3.预测概率
每个网格预测一个类别概率分布,即 C 个类别的概率(如图中下方的彩色 class map)。这些类别概率是与该网格是否包含物体无关的条件概率。
4.输出组合(Final Prediction)
对每个预测框,其最终得分 = 类别概率 × 置信度。最后利用 非极大值抑制(NMS) 去除冗余框,得到最终检测结果(如图最右侧)。
NMS(Non-Maximum Suppression)是目标检测中的一种后处理算法,用于从多个重叠的预测框中选择最靠谱的一个,去掉冗余和低质量的框。
3.模型结构
YOLOv1 架构由一个基于 GoogLeNet 的深层卷积网络 + 全连接层组成,最终将目标检测任务转化为一个 7×7×30 的张量预测问题,实现端到端的快速检测。
1.输入图像
输入尺寸为 448 × 448 × 3 的彩色图像
2.特征提取网络(Backbone)
• 使用了修改后的 GoogLeNet(Inception)结构,共 24 个卷积层 + 2 个全连接层,图中简化了
• 每个 “C, R” 代表一组卷积 + ReLU(激活)操作,特征图尺寸逐渐减小。
• 输出特征图尺寸为 7 × 7 × 1024。
3.全连接层 + 输出层
• 接上两个全连接层(如图所示):
• 第一个 FC 层:4096 单元
• 第二个 FC 层输出 1470 个值(对应 7×7×30)
YOLOv1 最终输出为一个大小为 7 × 7 × 30 的张量:每个 7×7 的网格单元(grid cell)输出 30 个值,具体为:
- 每个 grid cell 预测 2 个边界框(bounding box)
- 每个 bounding box 含有 5 个值:中心位置 (x, y)、宽高 (w, h)、置信度
- 每个 cell 还预测图像中包含各类别的概率,共 20 个类(Pascal VOC)
4.后处理(Post-processing)
将输出 reshape 为 7×7×30 后,使用 置信度 × 类别概率 得出每个 box 的最终得分,最后进行 Non-Maximum Suppression(非极大值抑制) 来去重并得到最终检测结果。
4.损失函数
YOLOv1 的损失函数是用在训练模型的时候,需要确保:
- 合理置信度(预测的置信度反映框内是否有物体)
- 准确定位(预测框的
x, y, w, h接近真实框) - 正确分类(预测的类别概率匹配真实标签)
通俗一点就是,你得准确地告诉我哪有东西(有置信度),框得要准(坐标误差小),别瞎说哪有东西(背景区域别胡说),而且你得看得出来这是只狗,不是猫(分类准确)。
大致可以拆分为四部分,分别对应于:
1.位置误差(坐标损失)
只对负责某个 object 的那个 bbox(bounding box)进行惩罚
- 仅对有物体的 cell 中,负责预测的那个 bbox 计算位置误差
- 用了 $\sqrt{w}$ 和 $\sqrt{h}$ 来降低大尺寸物体的影响
- $\lambda_{\text{coord}}$ 是位置损失的权重系数(论文中设为 5)
位置误差主要作用就是看框得准不准,框的位置和真实位置差多少。如果模型说「猫在这里」,那就要检查它预测的位置(x, y)、宽高(w, h)和真实的差多少。注意一点,位置误差只对真正有东西的格子负责。比如,猫在左下角,我预测在右上角,那我就要被扣分。
2.置信度误差(含有 object 的)
仅对包含目标的 cell 中,负责的 bbox 的置信度损失
- $C_i$ 是预测置信度,$\hat{C}_i$ 是 ground truth 的 IOU(即真实的)
如果格子里真的有东西(比如狗),你要给出一个高的「我很确定这有东西」的分数。如果你没信心,说“我不确定”,那也要被惩罚。
3.置信度误差(不含 object 的)
对没有目标的 cell 的所有 bbox 计算置信度损失
- $\lambda_{\text{noobj}}$ 通常设置为 0.5,防止大量背景区域主导损失
对于没东西的格子,如果你说「这有只猫」,那就太离谱了,要扣分!所以对于 背景区域(没目标),要特别注意别乱喊有目标。
4.分类误差
分类误差只对每个包含目标的 cell 进行,不涉及具体哪个 bbox。如果你预测框里有只猫,结果那是只狗,那也要扣分。所以还要学会看清楚「是猫还是狗」。
3.总结
1.物体检测评估指标总结
- TP/FP/FN/TN:
- TP:正确检测到正样本
- FP:误将负样本检测为正
- FN:漏检正样本
- TN:物体检测中通常忽略,因背景像素过多,计算无实际意义
- IoU:
- 预测框与真实框的交并比,IoU≥阈值(如0.5)判定为TP,否则为FP
- Confidence:
- 模型对检测框的置信度,用于过滤低置信预测和NMS排序
- Precision与Recall:
- Precision = TP / (TP + FP),衡量预测准确性
- Recall = TP / (TP + FN),衡量检出率
- PR曲线与AP:
- 调整置信度阈值生成PR曲线,AP为曲线下面积,反映模型综合性能
- VOC vs COCO:
- VOC:固定IoU=0.5,计算简单
- COCO:多IoU阈值(0.5-0.95),评估更严格,考虑小/中/大物体
2.YOLO-V1核心解析
- 核心思想
- 单阶段端到端检测:将检测转化为回归问题,直接输出边界框和类别
- 网格划分:图像分为7×7网格,每个网格预测2个边界框及20类概率
- 输出张量:7×7×30,其中每网格含:
- 2个边界框(各5参数:x, y, w, h, confidence)
- 20类概率(共享于网格内所有框)
- 模型结构
- Backbone:基于GoogLeNet的24层卷积+2层全连接
- 输出层:全连接层输出1470节点,重组为7×7×30张量
- 损失函数
- 坐标损失:仅计算负责物体的框,使用平方误差,λ_coord=5平衡权重$λcoord∑(x−x^)2+(y−y^)2+(w−w^)2+(h−h^)2$
- 置信度损失:
- 含物体:预测置信度接近IoU(平方误差)
- 不含物体:置信度趋近0,λ_noobj=0.5降低背景权重
- 分类损失:交叉熵损失,确保类别预测正确
- 局限性
- 每个网格仅预测固定数量框,密集小物体检测效果差
- 全连接层导致空间信息丢失,后续版本改用全卷积结构改进