基于循环神经网络的文本分类实践
1.循环神经网络(RNN)
环神经网络(Recurrent Neural Network, RNN)也叫递归神经网络,是专门处理序列数据的神经网络架构,其核心思想是通过循环连接使网络具备“记忆”能力,从而构建序列中时序之间的依赖关系。而处理具有时序或顺序关系的数据(如语言、语音、基因序列等)的核心挑战是理解序列中的上下文依赖关系。
RNN有隐藏状态(hidden state),可以保留和传递之前时刻的信息,也就是有记忆功能,从而可实现有上下文依赖性的数据处理:
通俗一点就像是人在读一句话:
- 读到 “我” → 记住
- 读到 “今天” → 结合前面的信息
- 读到 “很” → 继续理解上下文
- 读到 “开心” → 知道整体含义”我今天很开心“
1.RNN结构
RNN 通过隐藏状态(Hidden State) 存储历史信息,并通过时间步(Time Step)进行递归计算
- 输入层:接收当前时间步的输入 $x_t$
- 隐藏层:包含一个循环连接,用于存储历史信息:$h_t = f(W_h h_{t-1} + W_x x_t + b)$
- 输出层:根据隐藏状态计算输出 $y_t$
2.RNN 处理流程
1 | 输入序列 → RNN单元(时间步t=1)→ RNN单元(时间步t=2)→ ... → 输出 |
1.与卷积神经网络(CNN)对比
CNN是通过“卷积操作”提取图片中的局部特征,比如边缘、颜色、形状等,逐步构建对整个图像的理解。每个“卷积核”只看局部区域,不会直接处理整个图片。
CNN就像人类的大脑看图片时的处理方式:
- 第一层 识别边缘
- 第二层 识别形状
- 第三层 识别复杂的物体
- 最后输出 “这是一只猫🐱”!
1.CNN结构
- 卷积层(Convolutional Layer):使用卷积核(filter)提取图像局部特征
- 激活函数(ReLU):引入非线性,使网络可以学习复杂模式
- 池化层(Pooling Layer):减少特征维度,提高计算效率(如最大池化)
- 全连接层(Fully Connected Layer, FC):将特征映射到最终输出(如分类)
2.CNN处理流程
1 | 输入图像 → 卷积层 → ReLU → 池化层 → 卷积层 → ReLU → 池化层 → 全连接层 → 输出 |
3.CNN和RNN对比
| 特性 | 卷积神经网络(CNN) | 循环神经网络(RNN) |
|---|---|---|
| 主要用途 | 主要用于处理图像和空间数据 | 主要用于处理序列数据和时间依赖数据 |
| 数据类型 | 适用于静态数据(如图像) | 适用于动态数据(如时间序列、文本、语音) |
| 架构特点 | 采用卷积层和池化层提取局部特征 | 采用循环连接保持时间序列依赖性 |
| 计算方式 | 并行计算(卷积运算可并行化) | 依赖前序计算,难以并行化 |
| 长期依赖性 | 无长期依赖性,每个输入独立处理 | 具有记忆能力,可以捕捉长期依赖关系 |
| 梯度消失问题 | 无梯度消失问题 | 可能会遇到梯度消失(尤其是普通 RNN) |
| 训练难度 | 计算高效,易训练 | 计算较复杂,可能需要 LSTM/GRU 解决梯度问题 |
2.长短期记忆网络(LSTM)
RNN 本质上有“记忆”能力,但由于 梯度消失问题,它很难记住 较长时间前的信息。LSTM 通过 引入“门控机制”,可以 有效记住长期信息,避免梯度消失,使其能处理更长的序列数据。
1. 通俗理解LSTM vs. RNN
想象一下,你是一名学生,要上 一整天的课,然后参加 测验。
1.RNN
RNN就像是一个只有“短期记忆”的学生:
- 上午 8:00 上数学课,学了 微积分,你记住了一些公式。
- 上午 10:00 上英语课,学了 语法规则,你还记得大部分内容。
- 下午 2:00 上历史课,学了 第二次世界大战,但你开始忘记上午学的微积分。
- 下午 4:00 上物理课,学了 电磁学,但你基本已经忘了微积分和语法规则。
当 测验 需要你用 微积分 来解物理题时,RNN 学生发现:“糟糕!我已经不记得微积分怎么用了!” ,RNN 只能记住最近的知识,对于较早学的内容,信息会逐渐丢失(梯度消失问题)。
2.LSTM
LSTM 就像是一个擅长做笔记的学生,有一本“记忆笔记本”
- 上午 8:00 上数学课,你在笔记本上记录微积分公式。
- 上午 10:00 上英语课,你继续做语法笔记。
- 下午 2:00 上历史课,你决定删掉不重要的细节,但保留关键事件。
- 下午 4:00 上物理课,当你看到电磁学需要用微积分时,你翻开笔记本,找到微积分公式。
当 测验 要求你用微积分解物理题时,LSTM 学生发现:“太好了!我有笔记!我可以回忆起微积分!”
3.总结
- LSTM 有“记忆笔记本”(细胞状态),可以长期保存重要信息。
- LSTM 有“遗忘门”,可以丢弃不重要的信息(比如历史课不相关的细节)。
- LSTM 有“输入门”,可以选择性存入新知识(物理课需要微积分)。
- LSTM 有“输出门”,可以从记忆中提取正确的信息(在考试时用微积分解题)。
4.对比
| 对比点 | RNN(普通学生) | LSTM(做笔记的学生) |
|---|---|---|
| 能记住的信息量 | 只能记住最近的信息 | 可以记住更久的信息 |
| 信息丢失 | 早期学的知识逐渐遗忘 | 重要信息可以长时间保存 |
| 遇到复杂问题 | 可能忘记关键点 | 可以回忆笔记,找到答案 |
| 适合的任务 | 短文本、短时间序列 | 长文本、长时间序列 |
2.概述
1.数据集
现有train.txt(18万条)、dev.txt(1万条)和test.txt(1万条)三个数据集,分别对应训练集、验证集和测试集,每条数据格式都一样,下面是训练集前6条数据:
1 | 金证顾问:过山车行情意味着什么 2 |
金证顾问:过山车行情意味着什么为新闻标题,2为这个新闻对应的类别,对应class.txt中10类别的stocks。
目标:通过训练train.txt中的数据,生成模型,再推理test.txt中新闻标题对应类别,并计算准确度。
2.词汇表
vocab.pkl是词汇表,存储词汇到索引的映射,用于将文本转换为神经网络可处理的数字格式,有两个作用:
- 模型训练时,它用于将文本转换为索引(tokenization)
- 模型预测时,它用于将索引转换回单词(解码)
1 | {' ': 0, '0': 1, '1': 2, '2': 3, ':': 4, '大': 5, '国': 6, '图': 7, '(': 8, ')': 9, '3': 10, '人': 11, '年': 12, '5': 13, '中': 14, '新': 15, '9': 16, '生': 17, '金': 18, '高': 19, '《': 20, '》': 21, '4': 22, '上': 23, '8': 24, '不': 25, '考': 26, '一': 27, '6': 28, '日': 29, '元': 30, '开': 31, '美': 32, ... |
3.预训练词向量
预训练词向量(如 word2vec、GloVe)是在 海量文本数据(如 Wikipedia、新闻)上训练得到的,它们能够:
- 捕捉单词的语义关系(如 “king” - “man” + “woman” ≈ “queen”)
- 处理语境相似的单词(如 “big” 和 “large” 词向量相近)
- 减少训练数据对模型性能的影响(少量数据也能学得不错的表示)
预训练词向量 = 语言理解的“知识库”,能跨任务共享信息。embedding_SougouNews.npz和embedding_Tencent.npz是搜狗和腾讯提供的两个预训练词向量库。
4.训练数据转化流程
1 | # 1.训练集数据 (新闻标题 对应分类) |
2.数据处理
1.命令行参数配置
因为本次文本分类定义了两个模型,Text_CNN和Text_RNN,同时词向量映射支持搜狗和腾讯的预训练词向量和随机词向量,排列组合后有6种训练方式,为了方便可以使用命令行的方式配置参数:
1 | python run.py --model text_rnn --embedding sougou |
如果想在PyCharm中配置,Edit Configurations... -> Script parameters中添加:
1 | --model text_cnn --embedding tencent |
1 | # 通过命令行的方式指定参数 |
args.model和args.embedding就可以拿到对应参数
1 | model_name = args.model |
2.资源配置
1 | class SourceConfig(object): |
词向量参数如果设置为了random,词向量会在训练模型初始化的时候随机初始化词向量。
3.随机种子
在深度学习中,很多地方都会用到随机性,比如随机初始化模型参数、数据加载时的随机打乱、Dropout 层的随机性、优化器中的随机梯度下降等。
为了保证每次运行代码都会得到相同的结果,需要设置随机种子,保证每次运行代码时生成的随机数是相同的。
1 | np.random.seed(1) |
1 | def keep_seed(): |
4.加载dataset
在SourceConfig中添加了训练集、验证集和测试集的路径,还需要加载对应的训练集数据并通过词汇表转换为对应的索引映射。
1 | MAX_VOCAB_SIZE = 10000 # 词表长度限制 |
目前pad_size的大小设置是32,如果文本长度小于32的部分补齐PAD,超过部分则截断。如果文本中有字不在词汇表中无法映射,则用UNK替代,UNK和PAD分别对应的词汇表映射是4760和4761。
转换前的文本:金证顾问:过山车行情意味着什么
转换后的文本:
1 | [18, 249, 1086, 438, 4, 268, 169, 121, 46, 143, 274, 1342, 1068, 1046, 1081, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760, 4760] |
5.迭代器和toTensor
1.迭代器
可用于遍历可迭代对象(如列表、元组、字典、集合等)。Iterator 通过 __iter__() 和 __next__() 方法实现,允许我们逐个访问元素,也可以自定义一次遍历多个元素,举个简单例子
1 | class MyRange: |
自定义DatasetIterator迭代器,一次返回batch_size个元素,如果不满足batch_size则返回剩余元素
1 | class DatasetIterator(object): |
2.Tensor
将数据转换为 PyTorch 的张量(Tensor),并移动到指定的设备(CPU/GPU)以备模型训练
1 | def _to_tensor(self, datas): |
这一步可同时完成训练集验证集和测试集的Tensor数据准备
1 | train_iter = build_iterator(train_data, model.batch_size, source_config.device) |
3.模型定义
1.RNN模型
1 | class Model(nn.Module): |
1.模型属性
1.初始化词嵌入层
在初始化词嵌入层的时候,如果config.embedding_pretrained参数有设置,则使用预训练词向量,否则使用随机初始化的词向量
2.LSTM
用于处理 文本序列,捕捉 长期依赖信息
| 参数 | 作用 |
|---|---|
| config.embed | 词向量的维度(每个单词的向量表示大小,例如 300) |
| self.hidden_size | LSTM 隐藏层的维度(影响 LSTM 记忆能力,例如 128) |
| self.num_layers | LSTM 堆叠的层数(如 2,表示有 2 层 LSTM) |
| bidirectional=True | 双向 LSTM(前向和后向 LSTM) |
| batch_first=True | 输入数据格式为 (batch_size, seq_len, input_dim),即 batch 维度在第一位 |
| dropout=self.dropout | LSTM 层之间的 dropout 率,防止过拟合 |
双向 LSTM可以同时从 前向和后向 处理句子,增强了对前后文的理解,提高文本分类、命名实体识别等任务的效果
3.全连接层
因为使用了双向 LSTM (bidirectional=True),隐藏层的输出维度是 正向 LSTM 输出 + 反向 LSTM 输出,所以最终LSTM的输出维度是hidden_size * 2。
全连接层的输入维度必须是 256,最后将数据映射到 num_classes 个类别
2.前向传播
主要包括:解包输入、词嵌入、LSTM 处理、取最后时间步的输出、通过全连接层
x, _ = x,输入 x 是一个 元组,包含 (x, seq_len)只取xout = self.embedding(x),把 x 中的词索引转换成词向量out, _ = self.lstm(out),将词向量输入 LSTM,提取序列特征out = self.fc(out[:, -1, :]),out[:, -1, :]取序列的最后一个时间步的隐藏状态,形状变为 (batch_size, hidden_size * 2),为什么要取最后时间步?- 在文本分类任务中,我们通常只关心整个句子的表示,而不需要每个时间步的输出
- 方法:用 LSTM 处理整个句子,取最后的隐藏状态作为句子表示,再进行分类
3.模型参数
1 | <bound method Module.parameters of Model( |
2.CNN模型
1 | def conv_and_pool(x, conv): |
1.模型属性
1.初始化词嵌入层
在初始化词嵌入层的时候,如果config.embedding_pretrained参数有设置,则使用预训练词向量,否则使用随机初始化的词向量(同RNN模型)
2.卷积层
Conv2d(1, self.num_filters, (k, config.embed))
- 1 表示单通道输入(即词向量维度不变)
self.num_filters是 每种卷积核的数量,每个 filter 提取不同的 k-gram 组合(如 bi-gram、tri-gram)(k, config.embed)卷积核尺寸,k 控制窗口大小,embed 让每个 filter 作用于整个词向量
3.全连接层 & Dropout
self.dropout:防止过拟合。self.fc:将所有 filter 提取的特征拼接,然后进行分类:self.num_filters * len(self.filter_sizes):每个 filter 贡献 num_filters 维,多个 filter 拼接在一起
2.前向传播
out = self.embedding(x[0]):输入x是 (batch_size, seq_len),其中每个值是词索引out = out.unsqueeze(1): 变成四维,1 代表通道数(适配 Conv2d)out = torch.cat([conv_and_pool(out, conv) for conv in self.conv], 1):进行卷积和池化操作,对每个 filter 进行conv_and_pool,拼接不同 filter 提取的特征out = self.dropout(out):防止过拟合out = self.fc(out):全连接层,最终输出 out 形状(batch_size, num_classes),即每个样本的分类得分
3.模型参数
1 | <bound method Module.parameters of Model( |
4.训练模型
1.权重初始化
初始化神经网络中的参数,以提高训练的稳定性和收敛速度
1 | def init_network(model, method='xavier', exclude='embedding'): |
如果 name 包含 ‘embedding’,则跳过,不进行初始化。原因:
- 词嵌入层通常使用 预训练词向量(如 word2vec 或 GloVe)。
- 直接初始化可能会破坏预训练好的词向量结构
只对 权重 (weight) 进行特殊初始化。偏置 (bias) 一般设为 0,避免影响梯度更新。原因是bias 主要用于调整激活函数的输入值,不需要随机初始化。
Xavier 初始化:作用是保证输入和输出的方差一致,防止梯度消失或爆炸。
Kaiming 初始化:作用是避免 ReLU 可能导致的梯度消失问题。nn.init.normal_(w):使用正态分布随机初始化(均值 = 0,标准差 = 1),但不如 Xavier 或 Kaiming 稳定。
2.模型训练
大致过程:
- 计算损失和准确率
- 使用验证集评估模型
- 动态调整学习率
- 保存最优模型
- 支持早停(early stopping)
- 记录训练日志到 TensorBoard
1 | def train(config, model, train_iter, dev_iter, test_iter, writer): |
3.可视化训练过程
SummaryWriter 是 PyTorch 中 TensorBoard 的一个接口,用于记录和可视化训练过程中的各种信息(如损失、准确率、模型权重分布、图像、音频等),它可以帮助你更好地理解和调试模型。
1 | # 导入 |
下面是对模型CNN和RNN的训练过程可视化展示: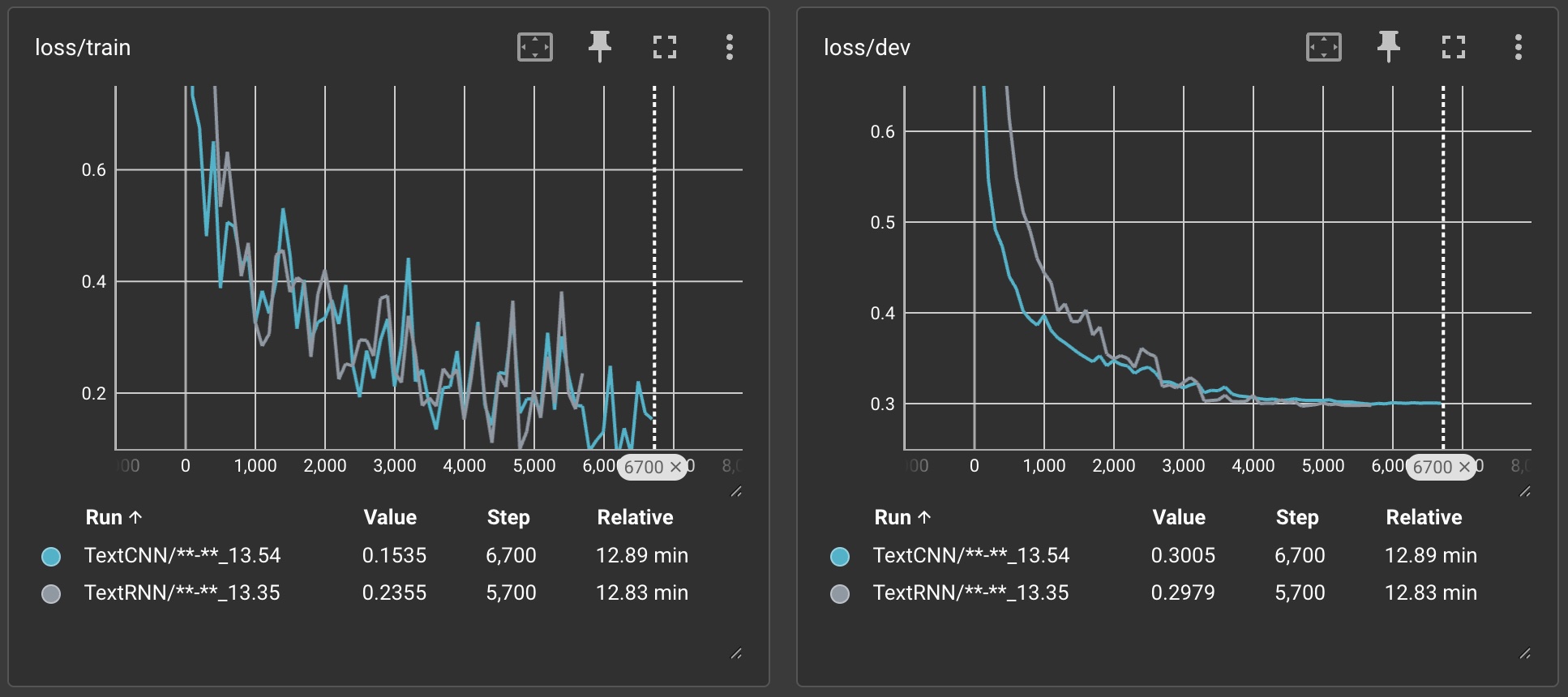
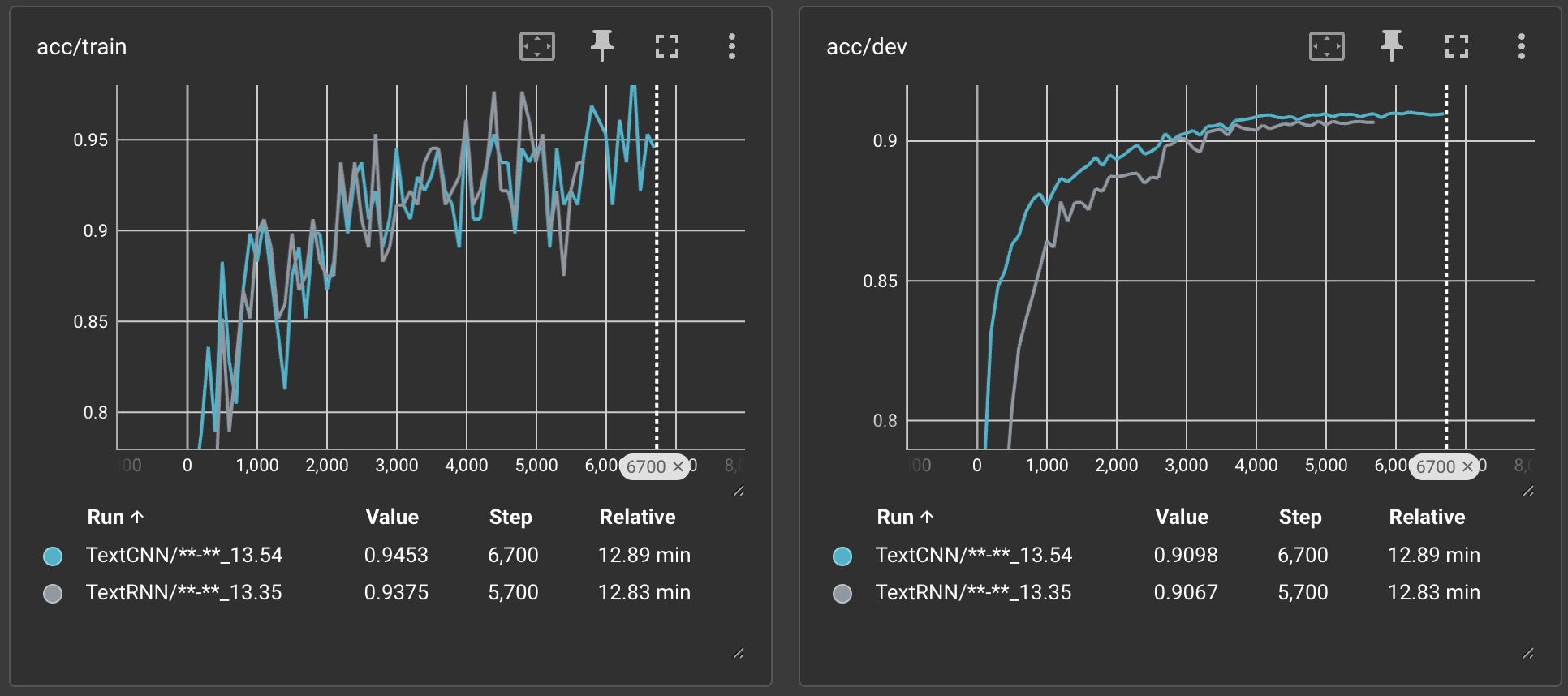
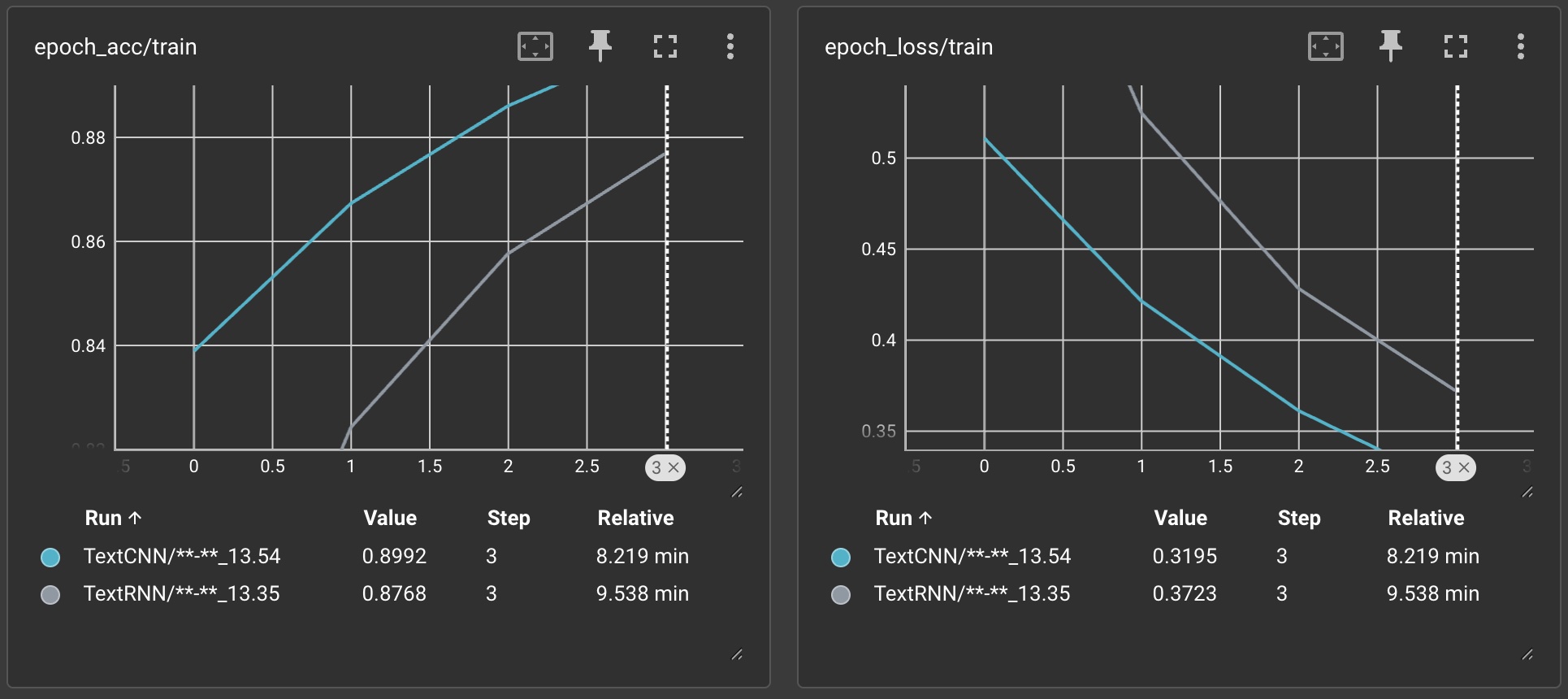
5.评估模型
1.评估函数
用于配合模型训练
如果 _test=False,只返回准确率 (accuracy) 和 损失 (loss)
如果 _test=True,返回 完整的分类报告和混淆矩阵
1 | def evaluate(config, model, data_iter, _test=False): |
2.评估模型
用于在测试集上评估模型的最终表现
1 | def _eval_result(config, model, test_iter): |
RNN模型评估结果:
1 | args model:text_rnn, embedding:sougou |
CNN模型评估结果:
1 | args model:text_cnn, embedding:sougou |
6.总结
本文涉及到的知识点:
- torch
- torch.nn:用于构建神经网络,如 Embedding、Conv2d、LSTM、Linear、Dropout 等
- torch.nn.functional:用于计算relu、cross_entropy、max_pool1d 等操作
- torch.optim:Adam 优化器和 torch.optim.lr_scheduler.ReduceLROnPlateau 进行动态学习率调整
- torch.Tensor:数据处理,包括 to(device) 用于 GPU 计算
- 文本处理
- 词嵌入 nn.Embedding 处理文本数据,支持 sogou、tencent 预训练词向量
- LSTM 和 CNN 进行文本分类 (TextRNN vs TextCNN)
- 词表 vocab.pkl的加载和构建 (pickle 序列化)
- 文本填充 (pad_size 处理变长文本)
- 数据处理
- DatasetIterator 设计了数据迭代器,支持 batch 训练,并进行 to(device) 加速计算
- build_iterator() 生成数据加载器,并支持 train/dev/test 迭代
- 训练与验证
- 训练 (train 函数),采用 Adam 优化器, ReduceLROnPlateau 进行学习率动态调整cross_entropy 计算损失,accuracy_score 计算准确率,早停机制 (require_improvement 防止长期无提升)
- 验证 (evaluate 函数):计算 loss 和 accuracy,在 test 评估时,输出 classification_report 和 confusion_matrix
- 日志可视化
- SummaryWriter 记录 loss 和 accuracy,支持 TensorBoard 可视化
- 命令行参数
- argparse 解析用户输入的 –model 和 –embedding选项
7.备注
环境:
- mac: 15.2
- python: 3.12.4
- pytorch: 2.5.1
- numpy: 1.26.4
- tensorBoard : 2.19.0
数据集:
https://github.com/keychankc/dl_code_for_blog/tree/main/005_rnn_classification_text/THUCNews/data
完整代码:
https://github.com/keychankc/dl_code_for_blog/tree/main/005_rnn_classification_text